

Guest Blog: Cyber risk and cybersecurity: A systematic review of data availability
The following article is a guest blog by Frank Cremer, currently a PHD candidate at the technical University of Cologne about his and his co-authors newest paper, systemtically tabulating and reviewing existing cyber risk and security research papers and datasets (). We highly recommend to check out the paper itself with its many interesting insights into, for example, the frequency of publications, showing a rapid increase in the last 5 years.
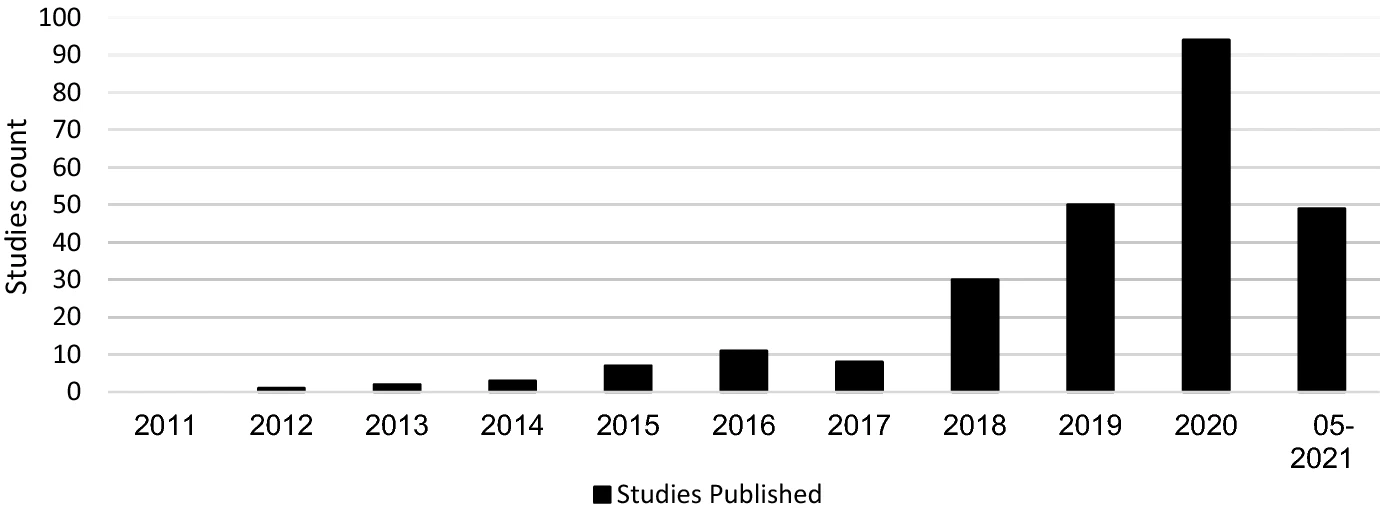
Fig 1: Frequency of Publications in Cyber Security
Cyber vulnerabilities pose a significant business risk, including business disruption, privacy breaches, and financial losses. Despite its increasing importance to the international economy, the availability of cyber risk data remains limited .
In our research, we found that the lack of available data on cyber risk is a serious problem for stakeholders seeking to address this issue. In particular, we noticed a gap in publicly available open databases that undermine collective efforts to manage these risks better. The reasons for this are many. First, this is an emerging and evolving risk; therefore, historical data sources are limited (). It could also relate to the fact that institutions that have been hacked do not usually make the incidents public ().
In a systematic literature analysis based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) framework , the databases IEEE Xplore, Scopus, Springerlink and Web of Science were used to identify studies based on predefined search terms. These studies were then reviewed using a list of criteria and either used for further research or excluded. Subsequently, the data sets on cyber risks and cybersecurity used in the studies were identified, analyzed and assigned to a category. The categories are also divided according to causes of cyber risks, impact of cyber risks, and cybersecurity. Some datasets were used interdisciplinarily, and they also appear in other categories.
In the causes of cyber risks categories, datasets were identified that examine the causes of cyber risks. The datasets help identify emerging trends and enable the revelation of patterns in cyber risks. This data provides cybersecurity professionals and cyber insurers with the data to make better predictions and take appropriate measures. For example, if specific exposures are not sufficiently protected, cyber insurers charge a risk premium, resulting in an improvement in the risk-adjusted premium. Because cyber risk is typically difficult to predict, existing data should be enhanced with new data sources (e.g., new events, new methods, or vulnerabilities) to determine the predictive cyber risk. Cyber risk root cause data sets could be combined with existing cyber insurer portfolio data and integrated into established pricing tools and factors to improve cyber risk assessment.
The next category, impact of cyber risks, can contain essential information, especially for cyber insurers. These datasets are an important source of information, as they can be used to calculate cyber insurance premiums, evaluate specific cyber risks, formulate inclusions and exclusions in cyber texts, and re-evaluate as well as supplement previously collected data on cyber risks. For example, information on financial losses can help better assess the loss potential of cyber risks. In addition, the datasets can provide insight into the frequency of occurrence of these cyber risks. The new datasets can be used to fill data gaps that were previously based on estimates or to find new results.
The last category covers the datasets of cybersecurity. In this category, by far the most data sets were determined, so a classification was necessary. These subcategories are as follows:
- General intrusion detection
- Intrusion detection systems with a focus on IoT
- Literature reviews
- New datasets
- Other
The first subcategory, General intrusion detection, deals with data sets that are primarily used for intrusion detection. Among other things, the data sets are used for pattern recognition, classification of intrusion possibilities and for testing purposes. The same applies to the category Intrusion detection systems with a focus on IoT. However, the priority of these datasets is on mobile devices. In addition to the other categories, reference should be made here to the New datasets category. These datasets aim to fix problems of old cybersecurity datasets and adapt their usability to more current circumstances.
References




